
Quantitative Methods (M), (UAC) & (H) Semester 1, 2021
Major Project
Introduction.
回归模型代写 定量方法 (M), (UAC) & (H) 2021 年第 1 学期
重大项目
介绍。
回归模型代写 Selling of houses is one of the things that has become a real challenge in todays time. In this project my main aim is to…
Selling of houses is one of the things that has become a real challenge in todays time. In this project my main aim is to make sure that I use the available to make predictions of the price of a house based on the features related to the house. The method I am going to employ here is to use the multiple linear regression to model the price of the houses as a function of the explanatory variables. The data in use will be from a small town called Junction which has 2 suburbs.
译文:出售房屋是当今时代真正面临的挑战之一。在这个项目中,我的主要目标是确保我使用可用数据根据与房屋相关的特征来预测房屋的价格。我将在这里采用的方法是使用多元线性回归将房屋价格建模为解释变量的函数。使用的数据将来自一个名为 Junction 的小镇,该小镇有 2 个郊区。
Data summary
The following table presents the summary statistics of the various variables;
. summarize AGE CRIME TOWN PRICE SIZE STORIES
数据汇总 回归模型代写
译文:下表显示了各种变量的汇总统计;
.总结年龄犯罪城镇价格大小故事
Variable | Obs Mean Std. Dev. Min Max
————-+——————————————————–
AGE | 540 14.97778 2.065591 8 21
CRIME | 540 2.496296 .8689582 1 3
TOWN | 540 52.44444 13.03437 30 60
PRICE | 540 417094.2 136082.8 55000 3230000
SIZE | 540 160.45 26.6797 89 450
————-+——————————————————–
STORIES | 540 1.159259 .422695 1 4
The summary statistics above are related to the numeric variables where I will use the mean of the variables to describe them. The houses have an average age of 14.9 which is 15 years. The average crime rate of 2.5 is really high in this area. Then our predictor variable which is the price has an average price of 417094.2 with the maximum price being 3230000 and the minimum price being 55000.
The following graph will help us understand the distribution of the dependent variable in this case I will use the histogram;
译文:上面的汇总统计与数值变量有关,我将使用变量的平均值来描述它们。 这些房屋的平均年龄为 14.9 岁,即 15 年。 2.5的平均犯罪率在这个地区真的很高。 然后我们的预测变量即价格的平均价格为 417094.2,最高价格为 3230000,最低价格为 55000。
下图将帮助我们理解因变量的分布,在这种情况下我将使用直方图; 回归模型代写
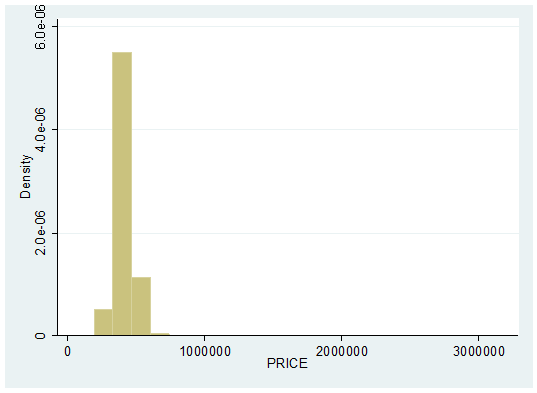
The distribution of the dependent variable is not normal in this case as we can see from the summary statistics and the graph that it rightly skewed.
译文:在这种情况下,因变量的分布是不正常的,正如我们从汇总统计数据和图表中看到的那样,它正确地倾斜了。

The table shows the frequencies of the seller that is W&M represents 0 which are the majority in this case 414 and A&B represented by 1 which shows that most houses have been sold by W&M company.
译文:该表显示了卖方的频率,W&M 代表 0,在这种情况下占大多数 414,A&B 代表 1,表明大多数房屋已被 W&M 公司出售。
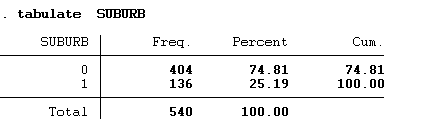
Mayfair (0) seems to have many of the houses that were sold as compared to Claygate (1) this can be seen from the frequency distribution above.
译文:与 Claygate (1) 相比,Mayfair (0) 似乎有许多已售出的房屋,这可以从上面的频率分布中看出。
Regression model
I had to run a regression model by adding and removing variables so that I may get the variables that explain the dependent variable very well.
Starting off with regressing the price to all the variables shows that some few variables are omitted due to collinearity. These variables contain different information. And as seen they are coded as numeric variables instead of being categorical in nature. The variables also did not have a higher R squared as is required so some changes had to be made.
回归模型
译文:我必须通过添加和删除变量来运行回归模型,以便我可以获得能够很好地解释因变量的变量。
从将价格回归到所有变量开始表明,由于共线性,一些变量被省略了。 这些变量包含不同的信息。 正如所见,它们被编码为数字变量,而不是本质上的分类变量。 变量也没有按要求具有更高的 R 平方,因此必须进行一些更改。
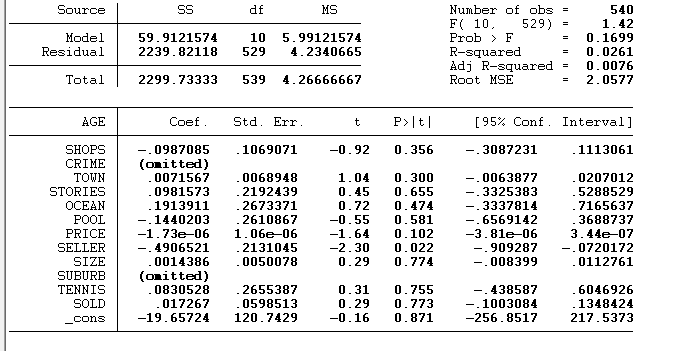
This is the model that comprises of all the variables. And as seen it has an R-squared of 0.0261 which is way too far from the required 88%.
So, the next step is to omit some of the variables that had the issues of collinearity. And then fit the model again. After trying out different variables. And fitting the regression model again I was able to get the following model fit which comprised. Of different explanatory variables explaining a variation 62.1% of the dependent variable (price).
译文:这是包含所有变量的模型。 正如所见,它的 R 平方为 0.0261,离所需的 88% 太远了。
因此,下一步是省略一些存在共线性问题的变量。 然后再次拟合模型。 在尝试了不同的变量之后。 并再次拟合回归模型,我能够得到以下模型拟合,其中包括。 不同的解释变量解释了因变量(价格)的 62.1% 的变化。
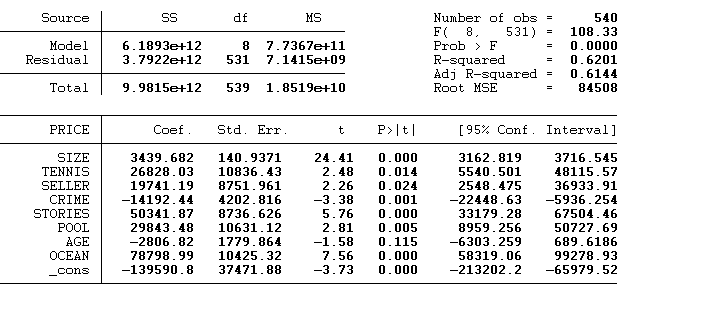
The model still did not prove to be more predictive because the R-squared was still low. So I had to transform the dependent variable by log transforming it. Because from the distribution we saw that it was skewed so I had to make it normal. With that the model produced an R-Squared of 70.67. which represents the proportion of variance in price explained by the explanatory variables.
译文:该模型仍未证明更具预测性,因为 R 平方仍然很低。 所以我不得不通过对数转换来转换因变量。 因为从分布中我们看到它是倾斜的,所以我必须使它正常。 该模型产生了 70.67 的 R 平方。 它表示由解释变量解释的价格方差的比例。
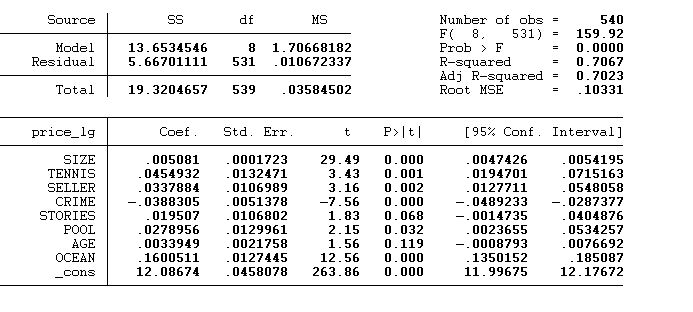
Therefore, my final regression model equation will a multiple one which will be;
Log_Price = 12.08674 + 0.005081*(SIZE) + 0.0454932*(TENNIS) + 0.0337884*(SELLER) – 0.0388305*(CRIME) + 0.019507*(STORIES) + 0.0278956*(POOL) + 0.0033949*(AGE) + 0.1600511*(OCEAN).
Using the regression equation above to make prediction for Kelly’s house.
译文:因此,我的最终回归模型方程将是一个倍数;
Log_Price = 12.08674 + 0.005081*(SIZE) + 0.0454932*(TENNIS) + 0.0337884*(卖方) – 0.0388305*(犯罪) + 0.019507*(STORIES)*06(STORIES)*016(05)*306(09)*05.06(0.0454932*(网球)+0.0337884*(卖方)) )。
使用上面的回归方程对凯利的房子进行预测。
Price = exp(12.09) + exp(0.005081)*189 + exp(0.0455)*1 + exp(0.0338)*0 + exp(-0.0388)*1 + exp(0.0195)*2 + exp(0.0279)*1 + exp(0.00339)*9 + exp(0.16) * 1 = 178280.3575.

The 90% predictive intervals for the sale price is [408,336.3634, 411366.5726]
I will advise Kelly to use W&M because the commission is too low and also they have a reputation of selling many houses as compared to the A&B.
译文:销售价格的 90% 预测区间为 [408,336.3634, 411366.5726]
我会建议凯利使用 W&M,因为佣金太低,而且与 A&B 相比,他们以出售许多房屋而闻名。
Regression model – evaluation
Running a Ramsey 1969 RESET test ( Regression Specification-Error Test) which checks for misspecification in the linear regression model.
回归模型——评估 回归模型代写
译文:运行 Ramsey 1969 RESET 测试(回归规范-误差测试),检查线性回归模型中的错误规范。

After running the test and with 0.05 significance level I will reject the null hypothesis. And conclude that we have some omitted variables. The next will be to test for non-linearity in the model.
译文:运行测试后,显着性水平为 0.05,我将拒绝零假设。 并得出结论,我们有一些遗漏的变量。 接下来将测试模型中的非线性。
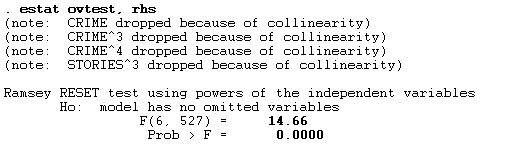
Again, using a significance level of alpha = 0.05 I get a significant result which means we have non-linearity in the model. What I did to deal with the mis specified part is I log transformed the outcome variable. And dropped some variables which were correlated. By log transforming the outcome variable it improved the proportion of variance that was explained. By the independent variables on the price, dropping the corelated variables also helped to increase the R-Squared. The data set had some issues that is it did not indicate if the variables were categorical. Or not and this really posed a problem for the model to identify the relationships very well and for making the predictions.
The data set available could not be used to make a better model that can be used to predict the sale price. This is because it had several issues that can not be modeled by the model well. So what I can mention is to say that the Kelly can prefer using different. And better models that can learn well from the data. With a better model we can have better predictions.
译文:同样,使用 alpha = 0.05 的显着性水平,我得到了显着的结果,这意味着我们在模型中具有非线性。我所做的处理错误指定的部分是我记录转换的结果变量。并删除了一些相关的变量。通过对结果变量进行对数转换,它提高了被解释的方差比例。通过价格的自变量,删除相关变量也有助于增加 R 平方。数据集存在一些问题,即它没有表明变量是否是分类的。或者不,这确实给模型很好地识别关系和做出预测带来了问题。
可用的数据集无法用于制作可用于预测销售价格的更好模型。这是因为它有几个问题不能被模型很好地建模。所以我可以提到的是,凯利可以更喜欢使用不同的。以及可以从数据中很好地学习的更好的模型。有了更好的模型,我们可以有更好的预测。


