
Home Schedule Lab

Computer Systems Organization
CSCI-UA.0201(007), Fall 2019
Lab-2: Rabin-Karp Substring Matching
Home Lab代写 Lab-2: Rabin-Karp Substring Matching.In this lab, you will write a program called rkgrep to find whether one (or more) patterns appears in a file
Due: 10/19
In text document processing, it is sometimes the case that we need to find out whether a (smaller) string appears somewhere in another (larger) string as a substring. For example, the UNIX utility grep allows you to search for one or more patterns in a file.
In this lab, you will write a program called rkgrep to find whether one (or more) patterns appears in a file. The goal of this lab is to help you improve your C programming skills e.g. manipulating arrays, pointers, number and character representation, bit operations etc.
Obtaining the lab code Home Lab代写
First, click on Lab2’s github classroom invitation link (posted in Piazza) and select your NYU email address. Next, clone your repo by typing the following
$ cd cso-labs $ git clone https://github.com/nyu-cso-fa19/lab2-<YourGithubUsername>.git lab2
This lab’s files are located in the lab2/ subdirectory. The files you will be modifying are rkgrep.c and bloom.c .
Part I: Naive matching
The most naive way of doing substring matching is to individually check whether a pattern string P matches the substring of length m at position 0, 1, 2, …, n-m in the document string Y.
Here, m is the length of the pattern string P and n is the length of document string Y. In other words, we are going to check whether P is the same as Y[0..m-1], Y[1..m], …, Y[n-m…n-1], where Y[0..m-1] is the substring of length m starting at position 0 of Y, Y[1..m] is the substring at position 1, and so on.
As an example, suppose the pattern string is “dab”, the document string is “abracadabra”. then you would check whether “ada” is the same as the substring at position 0 (“abr”), at position 1 (“bra”), … until you find a match at position 6.Home Lab代写
This naive algorithm is slow. If the pattern string is of length m, each check takes O(m) time in the worst case. Since there are total n checks, the naive algorithm takes O(m*n) to perform the substring match. Nevetheless, naive matching is extremely simple and so let’s get started on that.
Your job: Complete the function naive_substring_match in rkgrep.c file and test it by typing:
$ make $ ./rkgrep_test -a naive
Part II: Rabin-Karp Substring Matching Home Lab代写
The Rabin-Karp substring matching algorithm (short for RK) was invented in the eighties by two renowned computer scientists, Michael Rabin and Richard Karp.
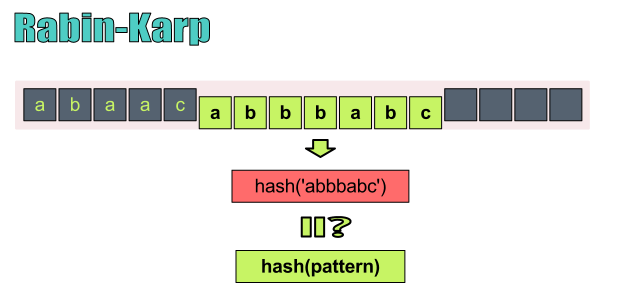
To check whether a given pattern string P appears as a substring in document string Y, RK uses the idea of hashing: A hash function turns a string of arbitary length into a b-bit hash value with the property that collision (two different strings having the same hash value) is unlikely.
At a high level, RK works by computing a hash for the pattern string of length m, hash(P), as well as hashes for all n-m+1 substrings of length m in the document string Y, hash(Y[0..m-1]), hash(Y[1..m]), …, hash(Y[n-m..n-1]), where Y[0..m-1] is the substring of length m at position 0 of Y, Y[1..m] is the substring at position 1 of Y, and so on. If hash(P) is identical to the hash at position i of Y, we can then perform the usual byte-by-byte comparison of P with the substring at position i to determine if P indeed matches at position i of Y.
There are many nice hash functions out there (such as MD5, SHA-256). but unfortunately, none of them would make RK any faster since they would take O(m) time to compute each of the n-m+1 hashes from Y. RK’s magical ingredient is its invention of a “rolling” hash function. Specifically, given hash(Y[i..i+m-1]), RK takes only constant time instead of O(m) time to compute the hash for the next substring, hash(Y[i+1..i+m]).
Let’s see how the rolling hash is done in RK. Home Lab代写
Specifically, we’ll treat each byte as a “digit” in a base-256 representation. For example, the string ‘ab’ corresponds to two digits with one being 97 (the ASCII value of ‘a’), and the other being 98 (the ASCII value of ‘b’). The decimal value of ‘ab’ in base-256 can be calculated as 256*97+98 = 24930. For a string P of length m, its RK hash is calculated as:
hash(P[0...m-1]) = 256m-1*P[0]+256m-2*P[1]+...+2561*P[m-2]+P[m-1] (1)
Next, let us see how a rolling calculation of the hash values is done. Let yi=hash(Y[i…i+m-1]). We can compute yi+1 from yi in constant time, by observing that
yi+1 = 256m-1*Y[i+1] + 256m-2*Y[i+2] + ... + Y[i+m] = 256 * ( 256m-2*Y[i+1] + ... Y[i+m-1]) + Y[i+m] = 256 * ((256m-1*Y[i] + 256m-2*Y[i+1] + ... Y[i+m-1]) - 256m-1*Y[i]) + Y[i+m] = 256 * ( yi - 256m-1 * Y[i]) + Y[i+m] = 256 * yi - 256m * Y[i] + Y[i+m] (2)
Note that in order to achieve constant time calculation, we have to remember the value of 256m in a variable instead of re-computing it each time.Home Lab代写
Now we’ve seen how rolling hash works. The only fly in the ointment is that these base-256 hash values are too huge to work with efficiently and conveniently. Therefore, we perform all the computation in modulo q, where q is chosen to be a large prime. (for those with a joint math major: why a prime instead of non-prime?)
Use modulo operations for all arithmetic
All the arithmetic operations done in Rabin-Karp, including addition, multiplication, exponentiation, should be done over a finite field using modulo operations.
With RK hashes, collisions are infrequent, but still possible. Therefore once we detect some yi = hash(P), we should compare the actual strings Y[i..i+m-1] and P[0..m-1] to see if they are indeed identical.
RK speeds up substring matching significantly. In particular, RK’s runtime is O(n) (since hash collusion is rare) compared with O(n*m) for the naive algorithm.
Your job: Implement the RK substring matching algorithm by completing the rk_substring_match procedure. To make your implementation modular and allows unit testing, we ask you to implement RK hash by writing two procedures, rkhash_init and rkhash_next .Home Lab代写
The procedure long long rkhash_init(const char *charbuf, int m, long long *h) takes as input a string pointer and a length m and returns the RK hash computed from scratch according to equation (1). It also returns the value of 256m by storing it in the long long variable pointed to by the third argument h.
The procedure rkhash_next(long long curr_hash, long long h, char leftmost, char rightmost) computes the next rolling hash given the current RK hash according to (2). Suppose yi is the current RK hash covering substring Y[i…i+m-1), then one can compute yi+1 over substring Y[i+1…i+m] by invoking rkhash_next(yi, h, Y[i], Y[i+m]). The second argument of rkhash_next must contain 256m.
Use modulo arithmatic
When calculating the hash values, you should use the given modulo arithmatic functions,
madd , mdel , mmul .
Testing: Test your implementation by typing
$ make $ ./rkgrep_test -a rk
The test prints out the measured running time. You should observe that the running time for RK is significantly faster than that of the naive algorithm.
Part III: Multi-pattern RK Matching with a Bloom Filter Home Lab代写
It turns out that RK is not the most efficient algorithm for performing single-pattern substring matching (i.e. matching just one pattern in a document). RK’s advantage is that it can efficiently match many patterns in the same document by storing the rolling hashes of the document and re-using it across patterns.
Let us assume that when we do multi-pattern matching, most of the patterns will not have any matches in the document. In this case, we can use a bloom filter to “store” rolling hashes in a kind of super-compressed way.
A Bloom filter is a bitmap of h bits initialized to zeros in the beginning.
To insert value v into the bitmap, we use f hash functions to map v into f positions in the bitmap and set each position to be one. For example, for a 8-bit bitmap and f=2, if v is mapped to positions 1,5, then the bitmap after insert v would be 01000100. Subsequently, suppose we also inserted v’ which is mapped to positions 0,3, the resulting bitmap would be 11010100.
There are many reasonable conventions with which we can use a byte array to represent a bitmap. In this lab, we expect you follow one specific convention and interpret bits in the Big- Endian convention within a byte. For example, we use a 2-byte-array to represent a 16-bit bitmap. The first byte represents the first 8-bit of the bitmap. And the most-significant-bit of the first byte represents the first bit of the bitmap. The most-significant-bit of the second byte represents the 9-th bit of the bitmap. Suppose the bitmap is 11010100 01000001, then the array content should be {0xe4, 0x41}.Home Lab代写
We can query the bloom filter to find out whether a value v might be present.
To do this, we check all f mapped positions of v. If all f bits are set in these mapped positions, then v is probably among the set of values inserted in the bitmap. We say that v is probably present because there can be false positives, i.e. v may not actually be present since a different value v’ may happen to have been mapped to the same positions as v (with a very small probability if the bitmap is large enough). Note that there are no false negatives (i.e. if bloom filter says v is not present, then v is definitely not present).
To use bloom filter for multi-pattern RK matching
we first create a bloom filter and insert all n- m+1 hashes for substrings of length m in the document to the bloom filter. Then, for each of the k patterns (assuming they all have the same length m), we check whether or not it is present in the bloom filter. If not, we can declare that the pattern is not present in the document and move on to check the next pattern. If yes, we then invoke our regular single- pattern RK function to confirm whether the pattern is indeed a match or not.Home Lab代写
If most patterns are non-matches, then this algorithm is very fast as it only takes a constant time to query the bloom filter.
Your job: First implement the Bloom filter functions by implementing the bloom_query , and bloom_add in the source file bloom.c .
To help you implement bloom_add and bloom_query , we provide you with a specific hash function implementation to map a value into a bitmap position, i.e. int hash_i(int i, long long x) . This function will hash a given Rabin-Karp hash value x into an int value according to the i-th hash function. Where i ranges from 0 to BLOOM_HASH_NUM-1. ( BLOOM_HASH_NUM is a global constant specifying the number of hash functions that you should use.) Note that you need to confine the resulting hash value to the appropriate range [0, bloom_bitmap_size) by using the modulo operation.
Testing: After you are done with the bloom filter implementation, test its correctness by typing Home Lab代写
$ make $ ./rkgrep_test -a bloom
Once your bloom filter passes the test, you can implement the multi-pattern RK matching by implementing the rk_create_doc_bloom and rk_substring_match_using_bloom in the source file rkgrep.c . Afterwards, test your implementation by typing:
$ make $ ./rkgrep_test -a rkbloom
Once you finish all parts, you can run all tests by simply typing ./rkgrep_test . This would run the tests for all parts one by one.Home Lab代写
Programming style:
As is the case with Lab-1, you will be graded for style and we will deduct up to 20% of total lab points for bad style based on our subjective evaluation. Please read this style guide and follow the advice.
Handin Procedure
To handin your files, simply commit and push them to github.com
$ git commit -am "Finish lab2" $ git push origin
We will fetching your lab files from Github.com at the specified deadline and grade them.
Bonus exercise: Boyer-Moore string matching Home Lab代写
The Rabin-Karp algorithm is pretty fast, but it still needs to scan every single character in the document string. Can we run faster than that? Can we avoid even having to look at every character in the document string? Surprisingly, the answer is yes, and the algorithm that achieves this sub-linear performance is called the Boyer-Moore string searching algorithm.
This algorithm is the one used by the UNIX command grep .
For the bonus exercise, implement Boyer-Moore by reading the first 4 sections of the original Boyer-Moore paper. You need to implement the init_delta1 , find_rpr , init_delta2 and boyer_moore functions in the bmgrep.c file.Home Lab代写
Test your implementation by typing:
$ make $ ./bmgrep_test

更多其他: prensentation代写 Case study代写 Academic代写 Review代写 Resume代写 Case study代写 心理学论文代写 哲学论文代写 计算机论文代写


您必须登录才能发表评论。