
CS525 – MidTerm
数据库代考 You are allowed to bring one page (both two sides can be used) of cheat sheet that must be turned in with the exam…
Instructions
- Things that you are not allowed to use
– Personal notes
– Textbook
– Printed lecture notes
– Phone
- You are allowed to bring one page (both two sides can be used) of cheat sheet that must be turned in with the exam
- The exam is 75 minutes long
- For your convenience the number of points for each part and questions are shown in parenthesis.
- There are 3 parts in this exam (70 points total)
- Disk Organization (10)
- Representing Data Elements (15)
- Index Structures (45)
Part 1 Disk Organization (Total: 10 Points) 数据库代考
Question 1.1 Disk Access (10 Points)
Consider a hard disk with the following specififications:
- 6000 RPM
- 3.5in in diameter
- 250GB usable capacity
- 100 cylinders, numbered from 1 (innermost) to 100 (outermost).
- Takes 1 +
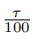 milliseconds to move the heads across τ cylinders (e.g., from i to i + τ ).
milliseconds to move the heads across τ cylinders (e.g., from i to i + τ ).
- Block size is 32 MB.
- transfer rate is 16 GB/sec.
- For this problem 1GB is 109 bytes, 1MB is 106 bytes.
(a) Based on the specififications, calculate the average rotational delay (in milliseconds) of this disk.
(b) Suppose that we have just fifinished reading a block at track 50, and we next want to read a block at track 10. What is the total read time (time for the desired block to appear in memory)? You can ignore the delays we ignored in class.
Part 2 Representing Data Elements (Total: 15 Points) 数据库代考
Question 2.1 Record Layout (15 Points)
Suppose we have blocks of size 1024 bytes that we use to store fifixed-length records. Each block has a 32 byte header used to store information including the number of records in the block.
(a) Suppose we have records consisting of a 12 byte header, and 3 fifields of size 5 bytes, 6 bytes and 7 bytes respectively. Within each record, fifields can start at any byte. How many records can we fifit in a block?
(b) Suppose that we have 3 records, each with a 12 byte header and 500 bytes of data.
i) How many blocks will we need to store these 3 records if no spanning is allowed?
ii) How much total free space is there in the blocks if no spanning is allowed? (Assume we are not storing anything else)
iii) How many blocks will we need to store these 3 records if spanning is allowed? In addition to the record header, each time a record is split into fragments, each fragment needs its own header of 12 bytes.
(c) Now consider blocks of size 1024 bytes that we use to store variable-length records. Each block has a fifixed 32 byte header used to store information including the number of records in the block. In addition to this fifixed header, the header contains variable number of 2 byte pointers to each record in the block. Records can start at any byte offffset and are packed as densely as possible. Which of these following combinations of records can be stored in a single block? Check all that apply. Show your work.
❑ 32 records of 23 bytes each
❑ 30 records of 20 bytes each and 10 records of 10 bytes each
❑ 5 records of 11 bytes, 10 records of 13 bytes and 20 records of 17 bytes
❑ 2 records of size 496
Part 3 Index Structures (Total: 45 Points) 数据库代考
Question 3.1 Conventional Indexes and and B+-Trees (15 Points)
Suppose the usable space on a disk page is 8,000 bytes for indexing. This is the space fifilled with key values and pointers. A key value and pointer pair is called an entry. The pointers in a leaf node point to tuples in a relation. Pointers in the upper levels point to index nodes at levels below. Each index node is mapped to a disk page (block) and all pointers are the same size: 16 bytes.
You are creating the following indices: index i1 on R(A) and index i2 on R(A,B,C) where attribute A is 4 bytes long, attribute B is 10 bytes long and attribute C is 8 bytes long.
First, compute the capacity of the nodes: maximum number of entries that can be stored in a node/disk page. Recall that each index node (internal or leaf) contains the same type of information and has the same capacity. You may have one extra pointer in each node, but we assume this is part of the header info that is not part of this computation. So you can safely disregard it. Assume each page contains about 75% of maximum number of entries (the root node or one of the nodes in each level may contain fewer nodes).
Given that Tuples(R)=500,000, compute the size of indices i1 and i2 (number of nodes at each level). Show your work.
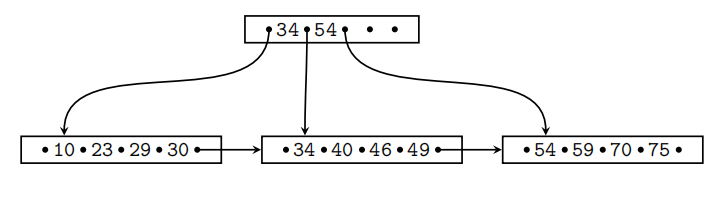
Question 3.2 B+ Operations (20 Points)
Consider a B+ -tree whose nodes contain up to 4 keys. Execute the following operations and write down the resulting B+ -tree after each step.
insert(80), insert(24), insert(42), delete(10), delete(40) 数据库代考
When splitting or merging nodes follow these conventions:
- Leaf Split: In case a leaf node needs to be split, the left node should get the extra key if the keys cannot be split evenly.
- Non-Leaf Split: In case a non-leaf node is split evenly, the “middle” value should be taken from the right node.
- Node Underflflow: In case of a node underflflow you should fifirst try to redistribute and only if this fails merge. Both approaches should prefer the left sibling.
Question 3.3 Hash Table Operations (10 Points)
Make the following assumptions:
- A bucket can hold two key-pointer pairs.
- The initial database D contains one object with key 10100.
Six objects with the following keys are inserted to D in the following order:
00110, 11010, 10011, 01010, 10110, and 01011.
- Assume that an extendible hash table is used to index the database. Show the index structure after the insertions. You have to show your work.


