CS525 – Midterm Exam Sample
数据库mid代考 You are allowed to bring one page (both two sides can be used) of cheat sheet that must be turned in with the exam…
Instructions
- Things that you are not allowed to use
– Personal notes
– Textbook
– Printed lecture notes
– Phone
- You are allowed to bring one page (both two sides can be used) of cheat sheet that must be turned in with the exam
- The exam is 75 minutes long
- For your convenience the number of points for each part and questions are shown in parenthesis.
- There are 3 parts in this exam (85 points total)
- Representing Data Elements (15)
- Relational Algebra and SQL (20)
- Index Structures (50)
Part 1 Representing Data Elements (Total: 15 Points) 数据库mid代考
Question 1.1 Record Layout (15 Points)
Suppose blocks of 1024 bytes are used to store variable-length records. The fifixed part of the block header is 24 bytes, and includes a count of the number of records. In addition, the header contains a 4-byte pointer (offffset) to each record in the block. The fifirst record is placed at the end of the block, the second record starts where the fifirst one ends, and so on. The size of each record is not stored explicitly, since the size can be computed from the pointers.
- How many records of size 50 bytes could we fully fifit (no spanning) in such a block? (The block is designed to hold variable size records, but these records by coincidence happen to be all the same size.)
- Suppose we want to fully store 20 records in the block, again all of the same size. What is the maximum size of such records?
- Now assume the block layout is changed to accommodate only fifixed size records. In this case, the block header is still 24 bytes and contains the common length of the records in the block. How many records of size 50 bytes could we fully fifit in such a block?
Part 2 Relational Algebra and SQL (Total: 20 Points) 数据库mid代考
You have been hired to work on a web site that maintains customer reviews of products. The main data is stored in the following tables:
- Product(pid:string, pname:string, description:string)
- Reviewer(rid:string, rname:string, city:string)
- Review(rid:string, pid:string,rating:integer, comment:string)
The tables contain the following information:
- Product: unique product id (pid), product name (pname), and product description. All strings.
- Reviewer: unique reviewer id (rid), and reviewer name (rname) and city, also all strings.
- Review: One entry for each individual review giving the reviewer and product ids, an integer rating in the range 0-5, and the reviewer comment, which is a string.
Write the following queries in SQL. No duplicates should be printed in any of the answers.
Question 2.1 (5 Points)
Return the ratings and comments from all reviews written by reviewers in Chicago for products named ‘ABC’. The results should be sorted in descending order by rating.
Question 2.2 (5 Points) 数据库mid代考
Return the number of reviewers in each distinct city. The results should list the city name and the number of reviewers in that city, and should be sorted alphabetically by city name.
Question 2.3 (5 Points)
Return the names of all grumpy reviewers. A grumpy reviewer is one whose average review rating is less than or equal to 2. If someone is in the Reviewer table but has no reviews in the Review table, they should not be included in the result. The reviewer names in the result can be in any order.
Question 2.4 (5 Points)
Return the names and descriptions of all cool products. A “cool product” is one that has no reviews in the database with any rating less than 4. A product must have at least one review in the database to be considered as a possible “cool product”. The results can be in any order.
Part 3 Index Structures (Total: 50 Points) 数据库mid代考
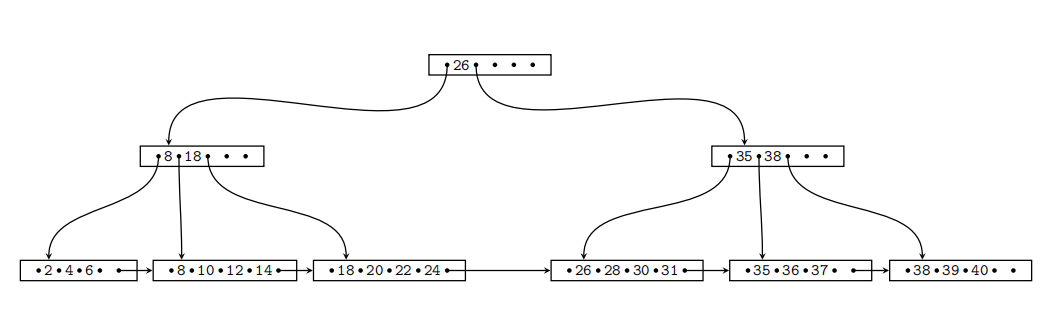
Question 3.1 B+-tree Operations (25 Points)
Given is the B+-tree shown below (n = 4 ). Execute the following operations and write down the resulting B+-tree after each step:
insert(1), insert(33), insert(17), delete(40), delete(26)
When splitting or merging nodes follow these conventions:
- Leaf Split: In case a leaf node needs to be split, the left node should get the extra key if the keys cannot be split evenly.
- Non-Leaf Split: In case a non-leaf node is split evenly, the “middle” value should be taken from the right node.
- Node Underflflow: In case of a node underflflow you should fifirst try to redistribute and only if this fails merge. Both approaches should prefer the left sibling.
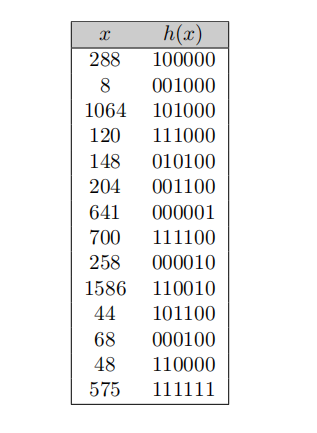
Question 3.2 Extensible Hashing (25 Points)
Suppose that we are using Extensible hashing on a fifile that contains records with the following search key values:
288, 8, 1064, 120, 148, 204, 641, 700, 258, 1586, 44, 68, 48, 575
Show the Extensible hash structure for this fifile if the hash function is defifined as below and buckets can hold 4 records each.