
machine learning & statistical inference final exam
机器学习final代考 These problems are worth 4 points each. You do not have to prove your answers; they will be graded based on the correctness of the boolean…
True or False 机器学习final代考
These problems are worth 4 points each. You do not have to prove your answers; they will be graded based on the correctness of the boolean values which you will write in the left margin.
(1) Backpropagation is a computationally efficient way of computing the gradient of a neural network, typically used as part of a gradient descent procedure to train the network.
(2) The maximum-likelihood estimator of an ordinary least squares (OLS) problem always exists and is unique for any design matrix X.
(3) The optimization problem that one must solve in Lasso regression is a non-convex optimization problem which can have multiple local minima.
(4) Let y be an n-dimensional real vector and X be an n × p real matrix. Consider minimizing

be a C∞ function that one is trying to minimize. Let x ∈ R n be the current point in an optimization algorithm, and suppose that d ∈ R n is a descent direction at x. Backtracking line search is an algorithm which finds the exact minimum of f(x + td) over all t ∈ R.
(8) More complex models always do better than simpler models on out-of-sample data (i.e. data that was not used in training the model).
(9) Logistic regression, neural networks, and support vector machines can all be used to train binary classifiers.
(10) When training a maximum-margin classifier of the type discussed in lecture, the optimal values of the parameters w, b depend sensitively on each and every one of the training samples’ coordinates.
-
Free Response
These problems are worth 15 points each. Partial credit will be given, so even if you cannot solve the problem perfectly, please try to get as far as you can.
Problem 1. Let f : R n → R be C∞, and let x ∈ R n. Derive the Newton step, by expanding f(x+v) to second order in v to get a function that is quadratic in x, and then finding the minimum of this quadratic. (Hint: the first-order term involves the gradient, and the second-order term involves the Hessian.) Is Newton’s method an effective optimization method for problems with large n? Why or why not? Is it effective for logistic regression when n is relatively small?
Problem 2. Consider a univariate regression model with no intercept: 机器学习final代考
Y = Xβ + ϵ, ϵ ∼ N(0, σ² )
where X and Y are scalar-valued random variables. You are given a list of observations
{(xi , yi) : i = 1, . . . , n},
where all xi ∈ R, and yi ∈ R.
(a) Express the least-squares estimate βˆ in terms of the vectors x = (x1, . . . , xn) and y = (y1, . . . , yn), assuming x is not the zero vector.
(b) Show that the vector ϵˆ defined by ϵˆ = y − βˆx is orthogonal to x.3
Problem 3. Describe the recursive binary splitting method for growing regression trees that was discussed in lecture. How does the algorithm choose which variable to split on? What criterion is minimized to determine the location of the split?
Problem 4. Consider a statistical estimation problem which can be written in the form min
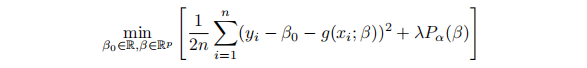
where λ controls the size of the penalty term, and hence also serves as a parameter to control model complexity. Suppose that you have access to a data set on which the model can be trained. Describe how you would set up and run a cross-validation study to determine the optimal value of λ for outof-sample prediction. How would you split the data in such a way that allows you to both determine the optimal λ, and also to obtain an unbiased estimate of the model’s forecast error variance on out-of-sample data?


