
STAT0030 Assessment 2 — Instructions
Assessment代写 For Question 1 you should submit online – on the course Moodle page – an electronic file containing your report for part (d).
1.Answer both questions.
2.ForQuestion 1 you should submit online – on the course Moodle page – an electronic file containing your report for part (d).
You are NOT required to submit your R script for this question.
3.ForQuestion 2 you should submit online – on the course Moodle page:Assessment代写
- An electronic copy of your r file, containing your R script (see below),
- an electronic file containing the graph in part (b) that is produced by your script,and
- anelectronic copy of your txt file (see below) containing output to parts (d), (e) and (f) produced by your R script.
Your R script for Question 2 should be saved in a file named StudentNumber.r, where StudentNumber is your student number. For example, if your student number is 18239004, your R script should be saved in the file 18239004.r.Assessment代写
Your script should create an output file called StudentNumber_out.txt, where again StudentNumber is your student number. This file should contain the output from parts (d), (e) and (f) and it should include text and comments indicating .what the results are (produced via appropriate use of the cat() function in your code). Any output should correspond exactly to what appears on the screen when sourcing your script file.
Your program should be well commented It should consist of a header section summarising the logical structure, followed by the main body of the script. The main body should itself contain comments.
4.Allrequired results for Question 1 Assessment代写
and your script for Question 2, should be submit- ted via the Moodle page for the course — use the link “ICA2: Click here to submit your assignment”. You can submit all results requested above on the Moodle via four separate electronic files: one file for Question 1, and three files for Question Make sure none of the files contains your surname, as the marking must be anonymous.
STAT0030 Assessment 2—Hints
1.Assessment代写
Ingeneral, there is not a single ‘right’ answer to each To obtain a good mark you should approach the questions sensibly and justify what you’re doing.Credit will be given for code that is clear and readable, while code that is inadequately commented will be penalised. You might like to use scripts cosapprox.r (Lab 1) and tablet.r (Lab 3) as models.
2.
Question1 is designed to test your ability to use the computer to learn about a real data set. This will be assessed not only on your computing skills, but also on your ability to carry out a sensible and informed statistical analysis: material from your other courses (in particular STATG0028) will be relevant To earn high marks for this question, you need to take a structured and critical approach to the analysis and to demonstrate appropriate judgement in your choice of material to present.
3.Assessment代写
InQuestion 2, make sure that the output for parts (d)–(f) is labelled appropriately so that the individual analyses can be See question 2 at the end of Lab 3 for an example of how to do this.
4.
Do not edit your txt file in any way before submitting it on Moodle. Markswill be deducted if this file does not correspond exactly to the results we obtain when we run the electronic files containing the R scripts.
5.Assessment代写
Morecredit will usually be given for code that is more generally applicable, rather than tailored to a particular situation or set of For example, if you were asked to print out the mean age of a group of people, you could do either of the following:
- Calculate the mean before you write your final script, and then insert aline
cat(“Mean age is 25.3\n”)
(or whatever the mean happens to be) into your script.
- In your script, create an object (say xbar) that holds the mean age, and then insert theline
cat(paste(“Mean age is”,xbar,”\n”))
into your script.Assessment代写
The second approach is clearly more general and will earn more credit, since it will work for other similar data also.
6.
Allgraphs should be clearly and appropriately labelled (giving units of quantitative variables), titled and By ‘appropriately formatted’ we mean, for example,that axis scales should be well chosen.
7.Assessment代写
Both questions carry equal
8.
Referto the feedback you received on in-course assessment
STAT0030 Assessment 2 – Marking guidelines Assessment代写
Questions 1 and 2 are each marked out of 30.
The marks for Question 1 are roughly subdivided into the following components.
- Exploratoryanalysis (10 marks): investigation and commentary of initial statistical properties, relationships, and anything of note which helps justify your choice of graphs and modelling
2.Graphicalpresentation (5 marks): appropriate choice of graphs and
- Modellingstrategy (10 marks): marks here will be based on a structured, justified, well-principled approach with clear and concise
4.Interpretationof final model (5 marks): commentary on how good the model is and what it means in reality in the context of the third part of Question
The marks for Question 2 are roughly allocated as follows:Assessment代写
- File handling and plotting, Parts (a) and (b) (5 marks): read in file; calculate and printquantities; be able to produce and format graph according to
2.Negative log-likelihood function, Parts (c) and (d) (10 marks): write negll() func- tionthat works and follows good programming practice (is usable, extensible, etc); has appropriate inputs and outputs; carry out appropriate Assessment代写
3.Optimisation,Parts (e) and (f) (10 marks): considerate and correct use of nlm()function, correctly compute standard errors.
- Style(5 marks): efficient, elegant, extensible, well-laid out, readable See also examples cosapprox.r (Lab 1) and tablet.r (Lab 3) for inspiration.
Marks will be deducted for code that a user would find ‘difficult’ to use. The ‘user’ here can either be (i) someone who cannot code and only knows how to run an R script and expects something meaningful to be produced on their screen or written to file; (ii) a fellow developer who would like to not only run your code but also understand how it works with a view to maybe building some of their own code on top of it. Generally, both of these user types should find your code useful and easy to use in order for you to get good marks.
STAT0030 Assessment 2 — Questions Assessment代写
1.Assessment代写
Thefile dat contains data from 32 cars.There are three quantitative variables: the horsepower (denoted by hp), the weight of the car in pounds (denoted by wt) and the fuel efficiency in miles per gallon (denoted by mpg). In addition there is an indicator variable tr denoting the gear transmission type, where 0 denotes automatic and 1 denotes manual. Engineers are interested in how the fuel efficiency depends on the horsepower and weight of the car and on whether this also depends on the transmission type.
a)
Download the file dat from the STAT0030 Moodle page. Read the data into R using read.table with the argumentheader=TRUE.
b)
Obtainsummary statistics for each quantitative variable for each transmission type, and make useful plots of the data — e., that are relevant to the objectives of the study. Such plots might include, but are not necessarily restricted to, pairwise scatter plots with different plotting symbols for the two transmission types. Put plots together in a single figure where appropriate and consider the possibility of using log scales for the quantitative variables.Assessment代写
c)
Finda linear model that enables mpg to be predicted from the other variables and that is not more complicated than necessary. You may wish to consider using log transformations of one or more of the explanatory variables or of the response You should consider a wide enough range of models to make your choice of model convincing and use appropriate diagnostics to assess them. But ultimately you are required to recommend a single model that is suitable for use (by engineers, for example) and to justify your recommendation.
d)
Write a brief report on your analysis in threesections:
I.Describe briefly what you found in your exploratory analysis in part(b)
II.Describebriefly (without too many technical details) what models you con- sidered in part (c) and why you chose the model you did, and
III.State your final model clearly and describe it in words. Remember to in- cludean estimate of the error standard deviation and say what this means also. Use your model to describe how the fuel efficiency depends on the transmission type (taking any other relevant variables into account). Also give an estimate of what would be the effect on the average fuel efficiency of increasing a car’s horse power (e.g., by 10 units or by a factor of 1.10). Give an appropriate assessment of the uncertainty in your
Your report should not include all of your R commands and output Assessment代写
but it should include some R commands and output (for example, relating to your final choice of model) and your most useful graphs. It should be limited to at most three pages of text (including any output) and two pages of graphs. Your report should be at a level that can be understood easily by somebody with an MSc in Statistics.
2.Assessment代写
The file dat contains estimates of “equivalent dose” (denoted by de) and their standard errors (denoted by se) for a number of individual grains of quartz. These were obtained by a technique called optically stimulated luminescence, which gives dose measurements in units called grays (Gy). An equivalent dose estimate yifor grain i is assumed to come from a Normal distribution with mean µ and variance σ2 + s2 . where µ and σ are unknown and si is the known standard error of the dose estimate yi. We wish to write a program to estimate µ and σ by maximum likelihood for data such as these. For data (yi, si), i = 1, 2, . . . , n, the log likelihood function is
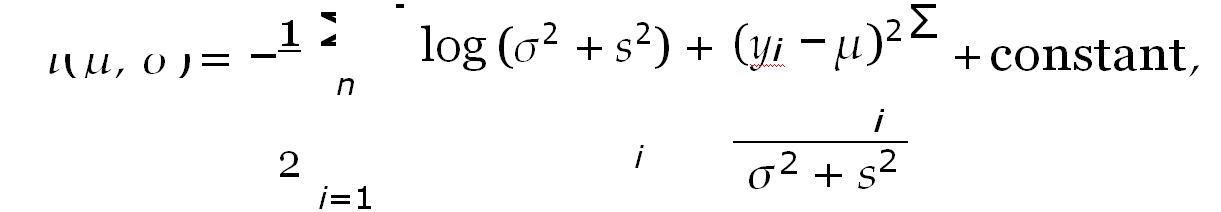
which is defined for σ ≥ 0 and for any µ (though in practice µ will be positive or possibly zero).
a) Downloadthe file dat from the STAT0030 Moodle page. Read it into Rusing read.table with the argument header=TRUE.
b) Plota figure with two panels, giving a scatter plot of se against de in the upper panel and a histogram of de in the lower Use the same de scale in both panels. Calculate the number of grains n and the mean and standard deviation of the equivalent doses and print these as text on your histogram. Label your figure and axes informatively.Assessment代写
c) Write a function called negll that takes twoarguments
i) params, a vector containing the values of the two parameters (µ, σ),and
ii) dat, a matrix of the datapairs,and returns the negative log-likelihood, −l(µ, σ), omitting the constant term from equation (1).
d) Use your function negll to evaluate and print out the negative log-likelihood for the data in datfor a few sensible values of µ and σ.
e) Usethe R function nlm to find and print out the maximum likelihood estimates of µ and σ for the data in dat by minimising the negative log likelihood.
f) Obtain and print out approximate standard errors for these Assessment代写

更多其他: 代写案例 Report代写 文学论文代写 艺术论文代写 人文代写 Case study代写 心理学论文代写 哲学论文代写 心理学论文代写 哲学论文代写 计算机论文代写


您必须登录才能发表评论。