
MgtF 405: Forecasting
Assignment 2 (due on January 28, 2019)
Forecasting代写 It contains monthly information on US stock returns as well as on a range of predictor variables proposed in the literature.

Part I. Model Selection Forecasting代写
This assignment uses the file Goyal_Welch_data2016.xlsx in the Assignment 2 folder on Triton ED. The data is downloaded from Amit Goyal’s web site and is an extended version of the data used by Goyal and Welch (Review of Financial Studies, 2008).
It contains monthly information on US stock returns as well as on a range of predictor variables proposed in the literature. We have also provided matlab and R codes for you to use in the analysis (available in the Assignment 2 folder).Forecasting代写
You are asked to estimate forecasting models and simulate their performance out-of-sample.
To do so, use data from 1927m1 to 1969m12 to estimate each forecasting model, then generate a return forecast for 1970m1. Then add the monthly data for 1970 to the estimation model and produce a forecast for 1970m2. Repeat this process until the end of the sample in 2016m12. This is called back testing or simulated out-of-sample forecasting.
Each forecasting model has the excess stock return as the dependent variable. Forecasting代写
The excess stock return is listed in column E (as a rate of return per month). As predictors you can choose from a list of 10 variables: the dividend-price ratio D/P (col F), earnings-price ratio E/P (col G), book-to-market ratio b/m (col H), T-bill rate tbl (col I), default-spread def_spread (col J), long-term yield lty (col K), net equity issues ntis (col L), inflation rate infl (col M), long-term returns ltr (col N), and stock variance svar (col O). The definition of these variables is explained in Goyal and Welch (2008).
Estimate linear regression models of the form (where yt+1 = excess returnt+1 from col. E)
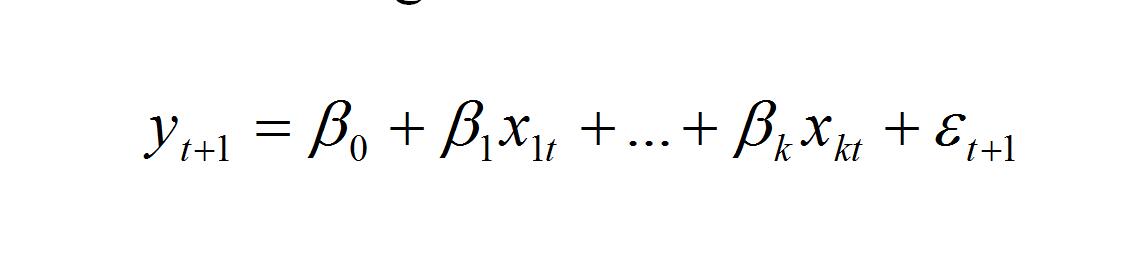
(1)
Make sure to use one-month lagged values of the predictors. Forecasting代写
Univariate models have only a single predictor x1. Multivariate models have two or more predictors x1, x2,…. All models include an intercept term.
1.
At each point in time where you are generating a forecast (1969m12, 1970m1, .., 2016m11) find a way to select a preferred forecasting model. You can do this by using stepwise selection methods (general to specific or specific to general) or you can do this by conducting an exhaustive model selection search over all 211 possible regression models, selecting the model by AIC or SIC. Forecasting代写
Or, you can use another method such as LASSO. Plot the forecasts against the actual values and report the root mean squared forecast error associated with the forecasts.
2.
How often does your preferred model selection approach include different predictor variables? [hint: compute the average of the number of times that a predictor gets selected over the sample from 1970 through 2016].
3.
Next, repeat the exercise when you use only a constant in the forecasting model. This is the prevailing mean (pm) model of Goyal and Welch and corresponds to a constant expected excess return. Again, compute the out-of-sample forecasts and the root mean squared forecast error from this model. Which produces the most accurate forecasts, your model in (1) or the prevailing mean model? Forecasting代写
4.
Repeat the exercise when you use the kitchen sink model that includes all 10 predictors (plus a constant). Plot the forecasts from this model and report the root mean squared forecast error. How well does this approach work?
5.
OPTIONAL/BONUS QUESTION: Replace the linear regression model in (1) with a machine learning model of your choice such as a regression tree, LASSO, or a neural net. How well does your approach work for same out-of-sample period used in question 1?
Part II: Chinese travels Forecasting代写
The excel file China_travels.xlsx contains monthly data on Chinese trips (in units of 10,000 trips) by rail (column B in the worksheet “travelers”) and by air (column C) over the period 1/1/2005 – 11/1/2018. The date of the Chinese New Year is contained in a separate worksheet (“Date of Chinese new year”).
1.
Plot the time-series for the two variables (rail and train trips). Briefly note the main features of the data (e.g., trend, seasonality).
2.
Propose and estimate a forecasting model for Chinese rail trips. Explain which terms you include and how you model any seasonality, trend and cyclical effects.
3.
Is the date of the Chinese New Year a significant predictor of monthly rail trips?
4.
Do air trips help you predict the number of rail trips, once you have included information on past (lagged) rail trips?
5.
Produce forecasts of the number of rail trips for December of 2018 and January and February of 2019 (i.e., three numbers).
Also included in the worksheet “baidu search index” is the number of searches for air tickets (using different Chinese terms) in columns B, C and D along with searches for train tickets (column E) and intercity bus tickets (column F). These are daily data.Forecasting代写
6.
Does the daily search data help you predict monthly rail or plane trips? Please report your preferred forecasting model and explains how/if it uses the Baidu search data. Make sure the search data is known prior to the month or which you are predicting the rail or plane trips (e.g., use September search data to predict October trips). You can use the full data sample up to 11/1/2018 to estimate your forecasting model.
更多其他:论文代写 网课代修 代写CS 数据分析代写 润色修改 代写案例 文学论文代写 商科论文代写 艺术论文代写 人文代写


您必须登录才能发表评论。